Google Music Playlist to CSV Using Pandas
Table of Contents
Recently I wanted to save the songs in my Google Music playlists as text files, but I couldn’t find a way to do it using the available menus in Google Music. It then occurred to me that I should be able to scrap a playlist web page to extract the data from a table element. To add a challenge to this task, I decided to use the Python pandas library to do it. As it turned out, it was a great decision that made the data clean up process very simple.
I start this post with the final outcome, the Python script songs.py that takes a Google music playlist file in HTML format as input and produces a text CSV file as output. Here is the command line on my terminal window:
./songs.py sr.html
saved file sr.csv with 156 songs
The input file sr.html contains the 156 songs from my Solid Rock playlist. I
created this file by first visiting the playlist Google web page and then
saving the page to my local hard drive. The playlist is small, but long enough
to illustrate the conversion process from HTML to CSV formats.
Web Scraping #
My first attempt to scrap the playlist’s web page with pandas was this line:
In [1]: import pandas as pd
In [2]: table = pd.read_html('https://play.google.com/music/listen...') # long URL here!
Out [2]: ...
ValueError: No tables found
The Google web page is complex, with lots of JavaScript code and links to
dynamic content loaders, but not a single HTML table is present. However, when I
save the page in the Web Page, complete format, which is the default in the
Firefox browser, I get one HTML file (sr.html) and a directory full of
images, scripts, CSS files, and many other elements. As it happens, this single
HTML file does have a table with the songs:
In [1]: import pandas as pd
In [2]: table = pd.read_html('sr.html')
In [3]: len(table)
Out[3]: 1
In [4]: len(table[0])
Out[4]: 41
The pandas read_html method scans the input and returns a list of DataFrame
objects, one per each HTML table it finds. Line 3 above tells me that pandas
found one table element and therefore there is one DataFrame in the list. Line 4
queries the number of rows in the DataFrame and finds only 41, not the 156 in
the playlist.
Here is what happens. The content of the page is generated dynamically but the output includes only enough songs to fill in the browser’s page, and a bit more, the exact number is unknown. The taller the display area becomes, for instance by reducing the page zoom, the higher the number of songs that are captured in the file. In my case I can capture 92 songs in a single file-save operation when the zoom is at its allowed minimum of 30% (the text is very small to read at this level). As I scroll past the first page, a new set of songs is generated which I can capture in a second file. Here are two screen shots side by side of the web page, 90% zoom on the left and 30% zoom on the right.
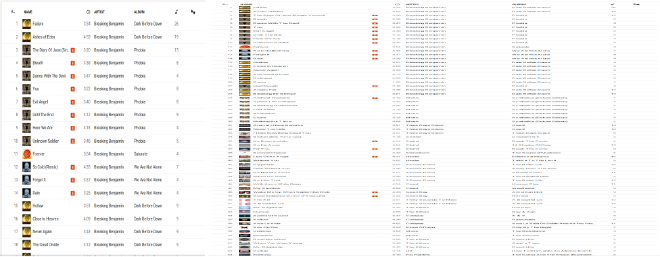
I decided then to minimize the zoom, save the HTML content as a file, press
Page Down, save the content again, and so on. The alternative was to look into
the JavaScript code and to attempt to do some magic to save the whole playlist
at once. But I stayed with the manual process because, first, my playlists are
not very long, and second, because I don’t want to learn JavaScript ☺.
I needed to save three files, sr{1,2,3}.html, to capture the 156 songs in my
Solid Rock playlist. I then concatenated them into a single file and used the
latter as the input to the songs.py script, as follows:
cat sr1.html sr2.html sr3.html > sr.html
./songs.py sr.html
saved file sr.csv with 156 songs
As a side note, you can concatenate the songs using pandas instead:
In [1]: import pandas as pd
In [2]: table1 = pd.read_html('sr1.html')
In [3]: table2 = pd.read_html('sr2.html')
In [4]: table3 = pd.read_html('sr3.html')
In [5]: table = pd.concat(table1 + table2 + table3)
Concatenating the three files, or equivalently, concatenating the DataFrames in pandas, results in a number of duplicate entries because some songs overlap in each captured file. This and other elements in the resulting DataFrame need to be addressed as part of a data clean up process.
Data Clean Up #
The first step after loading the HTML file is to look for information about the DataFrame of songs:
In [1]: import pandas as pd
In [2]: dfs = pd.read_html('sr.html')
In [3]: songs = pd.concat(dfs)
In [4]: songs.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 190 entries, 0 to 36
Data columns (total 7 columns):
# 182 non-null float64
Name 182 non-null object
Unnamed: 2 182 non-null object
Artist 182 non-null object
Album 182 non-null object
Unnamed: 5 180 non-null float64
Unnamed: 6 0 non-null float64
dtypes: float64(3), object(4)
memory usage: 11.9+ KB
There are 190 entries, including duplicates and invalid lines. There are seven columns of which I am interested in only three: Name (song name), Artist, and Album. The other four are # (song number), Unnamed: 2 (song duration), Unnamed: 5 (how many times a song has been played), and Unnamed: 6 (a thumbs up/down flag).
Let’s drop the unwanted columns and all rows with invalid (NaN) content (there are several of them):
In [5]: songs.drop(['Unnamed: 2', 'Unnamed: 5', 'Unnamed: 6'], axis=1, inplace=True)
In [6]: songs.dropna(inplace=True)
In [7]: songs.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 182 entries, 0 to 36
Data columns (total 4 columns):
# 182 non-null float64
Name 182 non-null object
Artist 182 non-null object
Album 182 non-null object
dtypes: float64(1), object(3)
memory usage: 7.1+ KB
Next is to eliminate duplicates, which are songs with the same value in the # column, and to drop that column which I don’t need anymore:
In [8]: songs.drop_duplicates('#', inplace=True)
In [9]: songs.drop('#', inplace=True, axis=1)
In [10]: songs.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 156 entries, 0 to 36
Data columns (total 3 columns):
Name 156 non-null object
Artist 156 non-null object
Album 156 non-null object
dtypes: object(3)
memory usage: 4.9+ KB
Excellent, now I have the right number of songs in the DataFrame, 156. What is left is to sort the entries by Artist → Album → Song name, re-index the dataset, and rearrange the columns in that order:
In [11]: songs.sort_values(by=['Artist', 'Album', 'Name'], inplace=True)
In [12]: songs.reset_index(inplace=True)
In [13]: songs = songs.reindex(columns=['Artist', 'Album', 'Name'])
Here are the first ten entries in the dataset:
In [14]: songs.head(10)
Out[14]:
Artist Album Name
0 3 Doors Down 3 Doors Down It's Not My Time
1 3 Doors Down Away From The Sun Here Without You
2 3 Doors Down The Better Life Be Like That
3 3 Doors Down The Better Life Kryptonite
4 3 Doors Down The Greatest Hits When I'm Gone
5 3 Doors Down Time Of My Life When You're Young
6 Against Me! Shape Shift With Me Crash
7 Alter Bridge Blackbird Rise Today
8 Audioslave Audioslave Like a Stone
9 Audioslave Out of Exile Be Yourself
Saving the DataFrame to a CSV File #
I derive the name of the CSV file from the name of the input file by changing
the suffix .html to .csv:
In [15]: from pathlib import Path
In [16]: path = Path('sr.html')
In [17]: csv = path.with_suffix('.csv')
In [18]: print(csv)
sr.csv
I can then generate the CSV file as follows:
In [19]: songs.to_csv(csv)
Back now to the command line on my terminal window:
head -11 sr.csv
,Artist,Album,Name
0,3 Doors Down,3 Doors Down,It's Not My Time
1,3 Doors Down,Away From The Sun,Here Without You
2,3 Doors Down,The Better Life,Be Like That
3,3 Doors Down,The Better Life,Kryptonite
4,3 Doors Down,The Greatest Hits,When I'm Gone
5,3 Doors Down,Time Of My Life,When You're Young
6,Against Me!,Shape Shift With Me,Crash
7,Alter Bridge,Blackbird,Rise Today
8,Audioslave,Audioslave,Like a Stone
9,Audioslave,Out of Exile,Be Yourself
If you do not want the index column and the header first row on the CSV file then use the following command:
In [20]: songs.to_csv(csv, index=False, header=False))
This is the new output:
head -11 sr.csv
3 Doors Down,3 Doors Down,It's Not My Time
3 Doors Down,Away From The Sun,Here Without You
3 Doors Down,The Better Life,Be Like That
3 Doors Down,The Better Life,Kryptonite
3 Doors Down,The Greatest Hits,When I'm Gone
3 Doors Down,Time Of My Life,When You're Young
Against Me!,Shape Shift With Me,Crash
Alter Bridge,Blackbird,Rise Today
Audioslave,Audioslave,Like a Stone
Audioslave,Out of Exile,Be Yourself
Mission accomplished!